[Effective Java] Item 13. clone 재정의는 주의해서 진행하라
clone() 메서드는 객체를 복제하는 데 사용된다. 이 메서드를 사용하여 객체를 복제하면 새로운 객체가 만들어지며, 이 객체는 원래 객체와 동일한 속성 값을 가지게 된다.
clone() 메서드는 기본적으로 얕은 복사를 수행한다. 객체의 원시 데이터 타입(int, double, boolean 등 객체가 아닌 데이터 타입)의 값을 복사하지만,
참조 타입의 값은 참조만 복사한다. 따라서 객체가 참조하는 다른 객체는 원래 객체와 복제된 객체가 모두 공유한다.
객체의 깊은 복사를 수행하려면 clone() 메서드를 오버라이딩 하고, 재귀적으로 복제하자.
clone()의 특징
- clone 메서드가 선언된 곳은 Cloneable이 아닌 Object이며 접근 지정자는 protected다.
- Cloneable을 구현하는 것만으로는 외부 객체에서 clone() 메서드를 호출할 수 없다.
- 따라서 clone()을 public으로 선언 후 오버라이딩 해야 한다.
Cloneable의 특징
그렇다면 메서드 하나 없는 Cloneable 인터페이스는 대체 무슨 일을 할까?
Object의 protected 메서드인 clone의 동작 방식을 결정한다.
Cloneable을 구현한 클래스의 인스턴스에서 clone을 호출하면 그 객체의 필드들을 하나하나 복사한 객체를 반환한다.
Cloneable을 구현하지 않은 클래스의 인스턴스에서 clone을 호출하면 CloneNotSupportedException을 반환한다.
인터페이스를 구현한다는 것은 응당 해당 클래스가 그 인터페이스에서 정의한 기능을 제공한다고 선언하는 행위이다. 하지만 Clonealbe의 경우에는 상위 클래스(Object)에 정의된 protected 메서드의 동작 방식을 변경한 것이다.
clone() 규약
Object 명세에 있는 clone 메서드의 일반 규약은 매우 허술하다.
복사의 정확한 뜻은 그 객체를 구현한 클래스에 따라 다를 수 있다.
일반적으로 이하 3개의 식은 참이지만 반드시 만족해야 하는것은 아니다.
x.clone() != x
x.clone().getClass() == x.getClass()
x.clone().equals(x)
관례상 이 메서드가 반환하는 객체는 super.clone()을 호출해 얻어야 한다. 이 클래스와 Object를 제외한 모든 상위 클래스가 이 관례를 따른다면 다음 식은 참이다.
x.clone().getClass() == x.getClass()
기본 타입 복제
학생 이름과 학번, 학점을 가지는 Student 클래스를 만들어 clone()을 구현해 보자.

clone() 메서드를 구현할 때 2가지 방식이 있는데 자세히 살펴보자.
1. super.clone()

사실 이렇게 할 수 도 있지만 자바에서는 공변 반환 타이핑을 지원한다. 따라서 오버라이딩한 메서드의 반환 타입은 상위 클래스의 메서드가 반환하는 타입의 하위 타입일 수 있다. 클라이언트가 형변환 하지 않아도 되게끔 바꿔주자.


2. 생성자 호출

이 클래스의 하위 클래스에서 super.clone()을 호출한다면 잘못된 클래스의 객체가 만들어져 하위 클래스의 clone() 메서드가 제대로 동작하지 않게 된다. 또한 복제할 객체의 필드가 많은 경우 매개변수가 많아져 코드가 복잡해질 수 있다. 복제할 객체의 타입이 변경되면 해당 클래스의 생성자도 수정해야 하므로 유지 보수가 어렵다.

두 방식 모두 잘 동작하긴 하지만 2번 방식은 쓰지 말자!
참조 타입 복제
clone 메서드는 원본 객체에 아무런 해를 끼치지 않는 동시에 복제된 객체의 불변식을 보장해야 한다.
만약 앞서 구현했던 방식으로 복제를 할 떄 클래스가 가변 객체를 참조하고 있었다면 어떻게 될까?
clone은 얕은 복사를 하므로 원본과 같은 객체를 참조할 것이다. 따라서 원본이나 복제본 중 하나를 수정하면 다른 하나도 수정되어 불변식을 해친다.
그렇다면 어떻게 해야할까?
해당 클래스의 내부 정보를 재귀적으로 복사해 깊은 복사를 하게 하자!
해당 예제는 Stack 클래스에서 Object [] elements 배열의 clone()을 재귀적으로 호출해 주었다.

만약 elements 필드가 final로 선언되어 있었다면 final 필드에는 새로운 값을 할당할 수 없기 때문에 이 방식은 작동하지 않는다.
하지만 Cloneable 아키텍처는 가변 객체를 참조하는 필드는 final로 선언하라는 일반 용법이 있어 이와 충돌한다.
주의할 점
1. clone() 메서드를 재귀적으로 호출하는것 만으로는 충분하지 않을 때가 있다.
해시테이블 내부는 버킷들의 배열이고, 각 버킷은 키-값 쌍을 담는 연결리스트의 첫 번째 엔트리를 가리킨다고 하자.
이때 위와 같은 방식으로 복제를 한다면, 복제본은 자신만의 버킷 배열을 갖지만 이 배열은 원본과 같은 연결 리스트를 참조한다. 따라서 각 버킷을 구성하는 연결리스트도 복사해야 한다.
2. Object의 clone() 메서드는 CloneNotSuppoertedException을 던진다고 선언했지만 오버라이딩 메서드는 그렇지 않다.
public clone() 메서드에서는 throws 절을 없애서 검사 예외를 던지지 않아야 그 메서드를 사용하기 편하다.
- 이를 호출하는 코드에서 반드시 예외 처리를 해주어야 해 코드의 가독성을 저해시킨다.
- 예외처리를 잊는 경우 런타임 예외가 발생할 수 있다.
- 복제를 할 수 없는 경우에는 객체를 복제하지 않고 null을 반환해 주자.
3. Cloneable을 구현한 스레드 안전 클래스를 작성할 때는 clone 메서드도 적절히 동기화시켜주자.
여러 스레드에서 동시에 객체를 복제하려는 경우 객체의 불변성을 유지하기 위해서 synchronize를 이용하여 clone() 메서드를 동기화해주자.
동기화하지 않은 경우 여러 스레드에서 동시에 복제를 시도하면 객체의 내부 상태가 불안정해져서 예측할 수 없는 결과를 가져올 수 있다.
복사 생성자와 복사 팩터리
복사 생성자와 그 변형인 복사 팩터리는 Cloneable/clone 방식보다 나은 면이 많다.
생성자를 쓰지 않는 방식을 사용하지 않는다. (일반적인 객체 생성 메커니즘을 따른다.)
엉성하게 문서화된 규약에 기대지 않는다.
정상적인 final 필드 용법과 충돌하지 않는다.
불필요한 검사 예외를 던지지 않고, 형변환도 필요하지 않다.
복사 생성자와 복사 팩터리는 해당 클래스가 구현한 인터페이스 타입의 인스턴스를 인수로 받을 수 있다.
즉, HashSet 객체 s를 TreeSet 타입으로 복제할 수 있다.
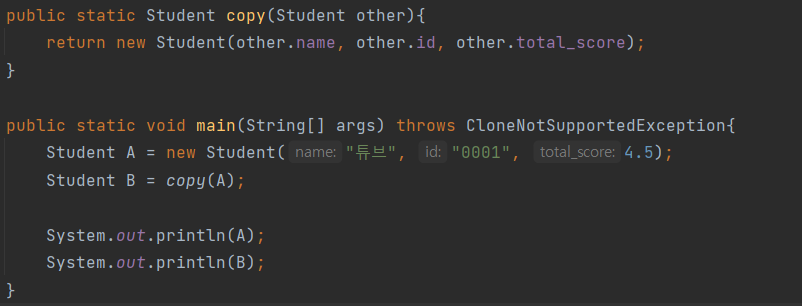
1. 복사 생성자

2. 복사 팩터리
결론
Cloneable을 구현하는 모든 클래스는 clone을 재정의 해야 한다.
이때 접근 제한자는 public으로, return 타입은 클래스 자신으로 변경한다.
가장 먼저 super.clone을 호출한 후 객체의 내부 깊은 구조에 숨어있는 모든 가변 객체를 복사하고, 복제본이 가진 객체 참조 모두가 복사된 객체를 가리키게 한다.
기본 타입 필드와 불변 객체 참조만 갖는 클래스라면 아무 필드도 수정할 필요 없다.
단 일련번호나 고유 ID는 기본 타입이나 불변일지라도 수정해줘야 한다.
하지만 새로운 인터페이스를 만들 때는 절대 Cloneable을 확장해서는 안되며 새로운 클래스도 이를 구현해서는 안된다.
복제 기능은 생성자와 팩터리를 이용하자.
단, 배열은 clone 메서드 방식이 가장 깔끔하다.